Gemma 4 merupakan langkah penting dalam industri AI yang menunjukkan pergeseran dari ketergantungan pada cloud menuju eksekusi lokal. Model ini dirancang untuk memberikan performa efisien pada GPU NVIDIA RTX dan mendukung kemampuan multimodal yang mencakup teks, gambar, video, dan audio.
Dirilis pada 3 April 2026, Gemma 4 memiliki beberapa varian, termasuk E2B, E4B, 26B, dan 31B. Model ini dibangun di atas fondasi teknologi yang sama dengan Gemini 3, dan dioptimalkan untuk eksekusi dengan latensi rendah pada perangkat keras lokal.
Gemma 4 mendukung lebih dari 35 bahasa dan telah dilatih dalam lebih dari 140 bahasa. Ini memungkinkan pengguna di berbagai belahan dunia untuk memanfaatkan kemampuan model ini dalam berbagai konteks.
Model ini dirilis di bawah lisensi Apache 2.0, yang memungkinkan penggunaan komersial secara gratis. Selain itu, Gemma 4 dapat beroperasi secara offline pada perangkat seperti Jetson Orin Nano, memberikan fleksibilitas bagi pengguna yang membutuhkan solusi AI tanpa koneksi internet.
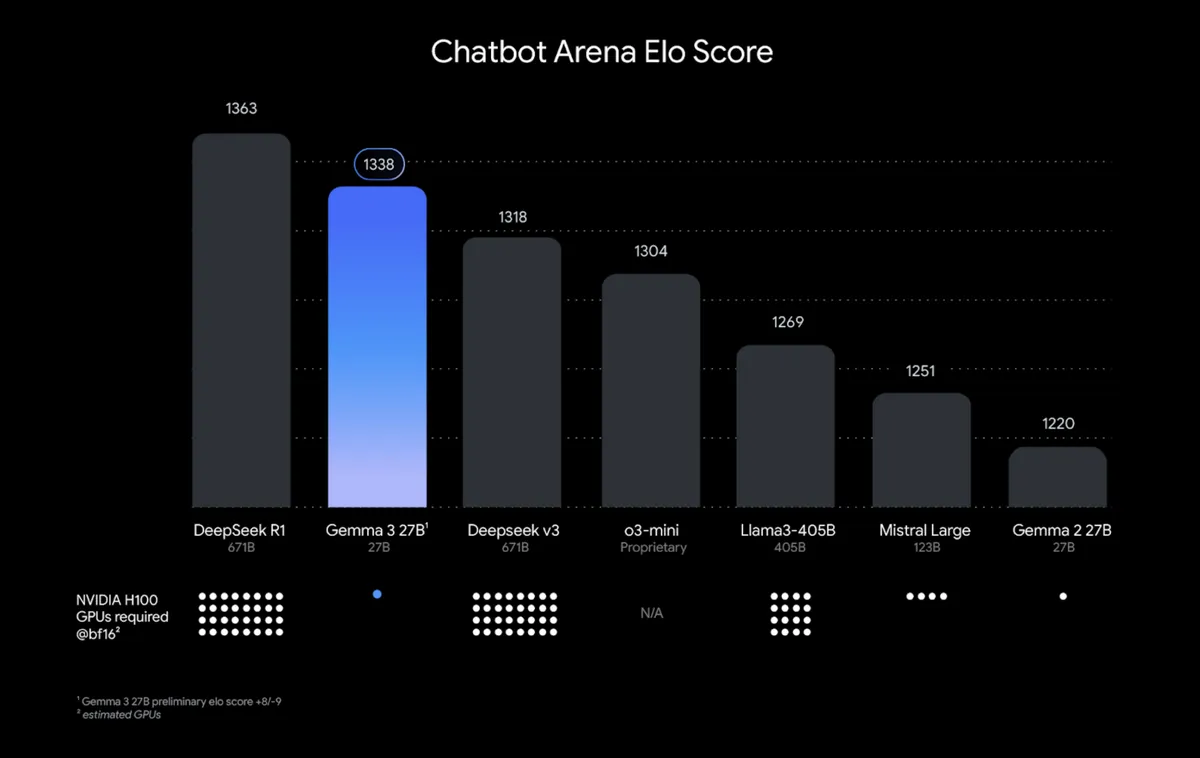
Model-model edge menawarkan ukuran jendela konteks sebesar 128.000 token, sementara model yang lebih besar mendukung hingga 256.000 token. Gemma 4 juga menempati peringkat ketiga di papan peringkat teks Arena AI di antara model open-source di seluruh dunia.
Dalam benchmark, model ini menunjukkan hasil yang kuat dalam matematika, pengetahuan ilmiah, dan pengkodean kompetitif. Model 31B, misalnya, mencatat skor 89,2% dalam matematika dan 80,0% dalam pengkodean kompetitif.
Integrasi dengan alat seperti Ollama, llama.cpp, dan Unsloth memudahkan implementasi lokal, memberikan pengguna akses yang lebih baik terhadap teknologi AI mutakhir.
Dengan peluncuran Gemma 4, para pengamat dan pejabat industri mengantisipasi peningkatan signifikan dalam penggunaan AI lokal di berbagai sektor, dari pendidikan hingga penelitian ilmiah.
Namun, rincian lebih lanjut mengenai penerapan dan dampak jangka panjang dari Gemma 4 masih perlu dikonfirmasi.













